
🇬🇧 Kubernetes Part 2
🇧🇷 para ler este artigo em português clique aqui
In this article series, we will explore Kubernetes in three parts. This is the second part, where I will explain tools and present exercises for you to put your acquired knowledge into practice. This will allow you to observe the pods running within the cluster and understand how each part of this system connects to create scalable and resilient applications.
Throughout the article, I will introduce various components and exercises separately, but it’s very important to understand that, together, they create a robust and scalable infrastructure. Kubernetes organizes resources using YAML files, which describe configurations such as pods, the basic units of execution. Elements like ReplicaSets and Deployments ensure high availability and consistent updates. Namespaces help isolate and organize resources, while Services and the Networking Infrastructure connect components to each other and to the external world. Features like Liveness Probes, Volumes, and Resource Management ensure monitoring, storage, and efficiency in complex environments.
With this in mind, let’s get started!
MINIKUBE:
As we will be learning and performing exercises, we need to prepare the Kubernetes environment to run our tests. If you don’t yet have Kubernetes and Minikube installed, I’ll provide a tutorial to help you set them up. But first, what is Minikube?
Minikube is a tool that allows you to create a local Kubernetes cluster on your computer. It is ideal for testing, development, and learning because you can run the entire Kubernetes setup without needing complex infrastructure or cloud services.
In practice, Minikube creates a virtual machine or container (depending on your system) and installs a basic Kubernetes cluster within it. This way, you can test your applications as you would in a “real” Kubernetes environment, but all locally. It also offers easy commands to manage the cluster, such as starting, stopping, adding extensions, and accessing the Kubernetes dashboard.
This video from the “CODIGO FLUENTE” channel will teach you how to set up your environment:
https://www.youtube.com/watch?v=Tr3l-cRIlmI
Watch it, and then come back here.
With Minikube installed, run the command:
minikube start
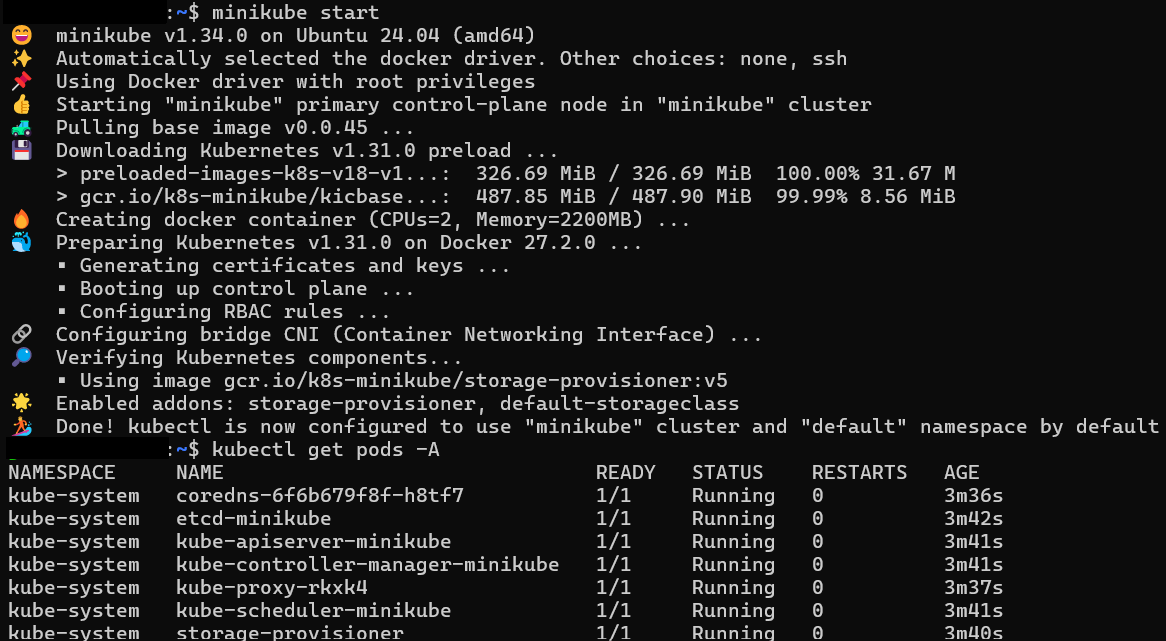
Now we are ready to get started.
YAML
YAML (Yet Another Markup Language, or currently YAML Ain’t Markup Language) is a data serialization format that is easy for humans to read and write. It is widely used for application configuration because it is simple and straightforward, yet powerful enough to support more complex structures like nested lists and maps.
The main idea of YAML is to be minimalist. Instead of using lots of braces and brackets like JSON, it uses indentation to organize data. This makes the file cleaner and easier to understand. Here’s a basic example:
name: Gustavo
age: 25
hobbies:
– watching series
– programming
– reading
work:
role: Data Engineer
experience: 6.5 years
In Kubernetes, YAML is the backbone. Everything you configure there—pods, deployments, services, volumes—is described in YAML files. These files tell Kubernetes what you want, and it makes it happen.
How does it work in Kubernetes?
YAML is used to define manifests that describe the desired state of resources. You write what you need, apply it with kubectl, and Kubernetes handles the rest.
Basic structure of a Kubernetes YAML file:
A file typically includes:
apiVersion: The API version you are using (e.g., apps/v1, v1).
kind: The type of resource you are creating (e.g., Pod, Deployment, Service).
metadata: Information like name and labels.
spec: The details of what you want to configure.
Basic example: Creating a Pod
apiVersion: v1
kind: Pod
metadata:
name: my-pod
labels:
app: my-app
spec:
containers:
– name: nginx-container
image: nginx:latest
ports:
– containerPort: 80
What it does:
kind: Pod: Specifies that you are creating a pod.
metadata: Provides the pod’s name and labels for identification.
spec: Configures the container, defines the image (nginx), and the port to be exposed.
Key points to be careful about:
YAML is unforgiving with indentation errors. A single misplaced space can break the file.
kubectl helps with validation: Use kubectl apply -f to check for errors before getting frustrated.
Be mindful of API versions—they change over time (e.g., extensions/v1beta1 is deprecated).
You can chain multiple resources in a single file by separating them with —.
With YAML in Kubernetes, you essentially describe what you want, and the cluster does the heavy lifting.
Later, we will create some pods and resources using YAML.
Pods:
Creating Pods – Imperative Approach:
Creating pods imperatively in Kubernetes is straightforward, quick, and great for testing something without creating a YAML file.
1. Simple Command:
Use kubectl run on the Minikube cluster we just started to create a pod directly:
kubectl run my-pod –image=nginx:latest

Pod created and running.
What happens:
Creates a pod named my-pod.
Uses the nginx:latest image from Docker Hub.
2. Adding a Port:
If your container exposes a port, you can specify it in the command:
kubectl run my-pod –image=nginx:latest –port=80
This is useful, for instance, if you want to connect via a service later.
3. Creating Pods with Environment Variables:
You can pass variables to the container:
kubectl run my-pod –image=nginx:latest –env=”ENV=production” –env=”DEBUG=false”
4. Generating the Pod’s YAML:
If you want to see the equivalent YAML and learn what it would look like:
kubectl run my-pod –image=nginx:latest –dry-run=client -o yaml
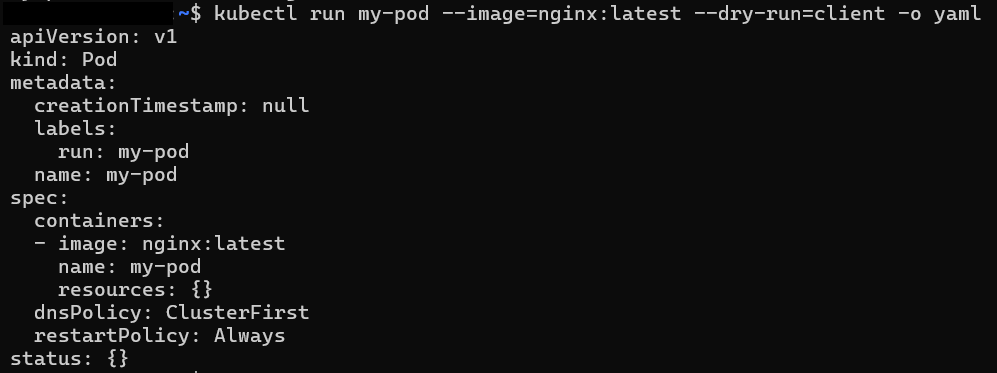
This only prints the YAML without applying anything. If you want to save it to a file:
kubectl run my-pod –image=nginx:latest –dry-run=client -o yaml > my-pod.yaml
Then you can edit it and apply it to the Minikube cluster:
kubectl apply -f my-pod.yaml
5. Listing Created Pods:
To check if your pod is running:
kubectl get pods

To view the details:
kubectl describe pod my-pod
6. Deleting the Pod:
When you no longer need it:
kubectl delete pod my-pod
Why Use the Imperative Approach?
- Quick Tests: No need to create and edit YAML for something simple.
- Learning: Helps you understand the available options in Kubernetes.
- Debugging: Quick to run and test containers directly on the cluster.
However, for more serious use cases, YAML is the best practice.
Creating Pods – Manifest Files:
Creating pods with manifest files is the declarative and organized way in Kubernetes.
1. Create the Pod YAML File
You can use any IDE to create a file named pod.yaml:
apiVersion: v1
kind: Pod
metadata:
name: my-pod
labels:
app: my-app
spec:
containers:
– name: nginx-container
image: nginx:latest
ports:
– containerPort: 80
What each part does:
apiVersion: Defines the API version. For Pods, it’s v1.
kind: Tells Kubernetes you’re creating a Pod.
metadata: Includes information like the name (my-pod) and labels (app: my-app).
spec: Defines what the Pod will contain, such as its containers.
containers: A list of containers in the Pod.
name: The name of the container.
image: The Docker image to use.
ports: The port the container will expose.
2. Apply the File to the Cluster
Use the kubectl apply command to create the Pod:
kubectl apply -f pod.yaml
If everything works correctly, Kubernetes will create the Pod.
Why Use Manifest Files?
Organization: Easy to version control with Git.
Reusable: Can use the same YAML across clusters.
Scalable: It’s the foundation for creating more advanced resources like Deployments and Services.
This approach is essential for production and understanding Kubernetes in daily operations.
ReplicaSets:
ReplicaSets are like the “guardians” of Pods in Kubernetes. They ensure that you always have the desired number of replicas running, even if a Pod dies or fails.
What is a ReplicaSet?
Purpose: Maintain a fixed number of active Pods.
How it works: If a Pod dies, the ReplicaSet creates another. If there are extra Pods, it removes the surplus.
Difference from a Deployment: ReplicaSets don’t manage version updates of Pods; that’s a Deployment’s job.
When to Use ReplicaSets?
In practice, you’ll almost always use Deployments because they already create and manage ReplicaSets for you. Only use a ReplicaSet directly for something very basic or for learning purposes.
Let’s Test It in Practice!
Creating a ReplicaSet
Create a file named replicaset.yaml with the following content:
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: my-replicaset
labels:
app: my-app
spec:
replicas: 3
selector:
matchLabels:
app: my-app
template:
metadata:
labels:
app: my-app
spec:
containers:
– name: nginx-container
image: nginx:latest
ports:
– containerPort: 80
What it does:
replicas: 3: Ensures 3 Pods are running.
selector: Specifies that it only manages Pods with the label app: my-app.
template: Defines how the Pods should be created.
Applying the ReplicaSet
Run the following command on the Minikube cluster to create the ReplicaSet:
kubectl apply -f replicaset.yaml
Check if it was created:
kubectl get replicasets
You will see something like this:
NAME DESIRED CURRENT READY AGE
my-replicaset 3 3 3 10s
Checking the Pods
The ReplicaSet automatically generated the Pods. Verify them:
kubectl get pods
You’ll see that the following Pods were created (the names after “replicaset-” might differ for you):
my-replicaset-abc12
my-replicaset-def34
my-replicaset-ghi56
Testing the ReplicaSet
Let’s test the ReplicaSet in action.
Delete a Pod manually:
kubectl delete pod my-replicaset-abc12
Now, see what happens:
kubectl get pods
The ReplicaSet will recreate the Pod you deleted. It ensures that there are always 3 Pods running.
Final Tip
You almost never create ReplicaSets directly in production. Instead, you use Deployments, which handle all the ReplicaSet tasks and also manage updates. However, understanding ReplicaSets is an excellent starting point.
Deployments:
Deployments in Kubernetes act as a “manual” that you provide to the cluster, instructing it on how to run and manage your Pods. With a Deployment, you define how your application should be deployed and kept operational.
What is it?
A resource used to create and manage Pod replicas.
Ensures your application is always running with the number of instances you define.
What do you configure?
In a Deployment YAML, you specify:
Container image (e.g., nginx:latest).
Number of replicas (e.g., 3 Pods).
Update strategies (e.g., “replace one at a time” or “take down all and start fresh”).
Labels and selectors to identify which Pods belong to the Deployment.
What does it do for you?
If a Pod fails, the Deployment automatically creates another.
For updates, it rolls out changes gradually (or as configured), to avoid downtime.
In Practice
Deployments run your application and ensure stability. However, if something goes wrong (e.g., a Pod gets stuck in CrashLoopBackOff), you’ll need to debug using kubectl logs or check Deployment events.
Creating a Deployment
Save the following YAML as deployment.yaml:
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-app
spec:
replicas: 2
selector:
matchLabels:
app: my-app
template:
metadata:
labels:
app: my-app
spec:
containers:
– name: my-app
image: nginx:1.23
ports:
– containerPort: 80
Quick Explanation
apiVersion and kind: Defines that this is a Deployment using apps/v1.
metadata: Specifies the name of the Deployment.
spec.replicas: Number of Pod replicas.
spec.selector.matchLabels: Determines which Pods belong to the Deployment (based on app: my-app).
spec.template: The Pod template.
metadata.labels: Labels for the Pod.
spec.containers: Container configuration:
name: Name of the container.
image: Container image to use.
ports: Port exposed by the container.
Apply the Deployment
Use the kubectl apply command to create the Deployment:
kubectl apply -f deployment.yaml
Verify the Deployment
Check if the Deployment is running:
kubectl get deployments
You’ll see something like:
NAME READY UP-TO-DATE AVAILABLE AGE
my-app 2/2 2 2 10s
Deployment Rollout
Deployment rollout is the process of releasing a new version of an application to production gradually and in a controlled manner to avoid widespread issues in case something goes wrong. Essentially, it replaces the old version with a new one cautiously, testing changes as they are applied.
Why Perform a Rollout?
If you simply update the entire application at once (the infamous “big bang deployment”) and there’s a critical bug, it can bring everything down. With a rollout, issues can be caught in smaller stages, making it easier to roll back to the previous version.
Rollout Examples
Rolling Update (Continuous Update):
Imagine you have 10 replicas of your application running in Kubernetes. With a rolling update, you update one or two replicas at a time. During the process, some replicas will still be running the old version, ensuring stability while you verify that the new version works as expected.
Example in Kubernetes:
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
This ensures that no more than one replica will ever be unavailable.
Canary Deployment:
This approach deploys the new version to a small percentage of users at first. If it performs well, you gradually increase the percentage until it reaches 100%.
It’s like testing a bridge with one car before opening it to full traffic.
Practical example: You have an application serving 100% of traffic. Configure a load balancer to send 10% of requests to the new version (v2), while the remaining 90% continue to the stable version (v1).
Rollout History
Rollout history tracks the versions deployed to your application. It’s helpful to understand what changed, identify when something went wrong, and even revert to a previous version. Kubernetes makes this process easy to manage and track.
In Practice with Kubernetes:
View rollout history:
To see the deployment history:
kubectl rollout history deployment <deployment-name>
Example:
kubectl rollout history deployment my-app
Expected output:
deployment.apps/my-app
REVISION CHANGE-CAUSE
1 Initial deployment created
2 Added new feature X
3 Bug fix in the API
Describe a specific revision:
To get details about a specific revision:
kubectl rollout history deployment <deployment-name> –revision=<number>
Example:
kubectl rollout history deployment my-app –revision=2
Output:
deployment.apps/my-app with revision #2
Containers:
– Name: my-app
Image: my-image:2.0
Port: 8080
Environment Variables:
– ENV: production
Rollback to a previous version:
If the current version is breaking, revert to the last stable version:
kubectl rollout undo deployment <deployment-name>
Example:
kubectl rollout undo deployment my-app
Or to a specific revision:
kubectl rollout undo deployment my-app –to-revision=2
Summary
Use rollout history to track changes.
Add reasons (–record) for easier tracking.
Quickly rollback in case of issues.
Rollout Pause and Rollout Resume
Rollout Pause:
This Kubernetes command halts the deployment update process. It’s useful when you need to:
Analyze if the new version is stable before proceeding.
Make manual adjustments to the deployment while it’s paused.
How to pause a rollout:
kubectl rollout pause deployment <deployment-name>
Example:
kubectl rollout pause deployment my-app
What happens?
The deployment stops updating Pods to the new version.
Already created Pods continue running, but no new replicas are updated.
Rollout Resume:
Once adjustments are complete or the new version is confirmed stable, you can resume the paused rollout. Kubernetes will continue the process from where it left off.
How to resume a rollout:
kubectl rollout resume deployment <deployment-name>
Example:
kubectl rollout resume deployment my-app
What happens?
Kubernetes resumes updating the remaining Pods.
The rollout continues following the defined strategy (e.g., RollingUpdate).
Deployment Scale
Deployment Scale refers to the ability to dynamically adjust the number of replicas of an application running in a Kubernetes cluster. In simple terms, it’s like scaling the “size” of your application to handle more (or less) traffic.
When to Use?
High Demand: Scale up to add more replicas when application traffic increases.
Cost Efficiency: Scale down during low-usage periods to save resources.
Resilience: More replicas help keep the application available even if some pods fail.
How It Works in Practice
Manual Scaling:
Adjust the number of replicas manually using the kubectl scale command.
Basic Command:
kubectl scale deployment <deployment-name> –replicas=<desired-number>
Example:
kubectl scale deployment my-app –replicas=5
Kubernetes ensures that 5 pods are running for the my-app deployment.
Check the Status After Scaling:
After scaling, verify the status:
kubectl get pods
This will show new pods being created or deleted.
Automatic Scaling (Horizontal Pod Autoscaler):
Instead of manual scaling, Kubernetes can automatically adjust the number of replicas based on metrics like CPU or memory usage.
Create an Autoscaler:
Use the kubectl autoscale command:
kubectl autoscale deployment <deployment-name> –min=<min-replicas> –max=<max-replicas> –cpu-percent=<target-percentage>
Example:
kubectl autoscale deployment my-app –min=2 –max=10 –cpu-percent=80
Kubernetes maintains between 2 and 10 replicas.
It scales up if a replica’s CPU usage exceeds 80%.
Monitor the Autoscaler:
Check the status:
kubectl get hpa
Output example:
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS
my-app Deployment/my-app 75%/80% 2 10 4
Here, 75%/80% indicates the current CPU usage is 75%, near the 80% limit.
Recreate Strategy Type
Recreate is a Kubernetes deployment strategy where all existing pods of an application are removed before creating new ones. It’s straightforward: shut down the old and bring up the new, with no overlap.
When to Use Recreate?
Incompatibility: When the old and new versions of the application cannot run together.
Unique Dependencies: If the application depends on a single resource (e.g., a database connection) that multiple instances might conflict over.
Simplicity: For quick updates in systems that can tolerate downtime.
How to Configure Recreate:
Set this in the deployment configuration file under spec.strategy.type.
Example YAML with Recreate:
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-app
spec:
replicas: 3
strategy:
type: Recreate
template:
metadata:
labels:
app: my-app
spec:
containers:
– name: my-app
image: my-app:2.0
ports:
– containerPort: 8080
When you apply a new version, Kubernetes deletes all old pods first and then creates the new ones.
Kubernetes Networking Infrastructure
Kubernetes Networking is like a system of “streets and addresses” ensuring everything in the cluster can communicate. Each Pod gets its own IP address, and communication is open by default (which can be risky).
Key Concepts:
Pods Communicate with Pods: They can reach each other regardless of location.
Services Act as Street Signs: Provide stable addresses to access pods, even as pods are created or deleted.
Ingress Acts as a Doorman: Manages external access to the cluster.
Quick Examples:
ClusterIP (Internal):
Used for services that only applications within the cluster can access.
NodePort (Fixed Port):
Opens a fixed port on each node for local testing.
LoadBalancer (Public):
Exposes a service to the internet through a cloud provider, like AWS or GCP.
Example Service YAML for an App on Port 8080:
apiVersion: v1
kind: Service
metadata:
name: my-app
spec:
selector:
app: my-app
ports:
– port: 80
targetPort: 8080
Ingress (HTTP Routing):
Direct traffic like mysite.com/api to the backend and mysite.com to the frontend.
Example YAML:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: my-ingress
spec:
rules:
– host: mysite.com
http:
paths:
– path: /
pathType: Prefix
backend:
service:
name: frontend
port:
number: 80
– path: /api
pathType: Prefix
backend:
service:
name: backend
port:
number: 80
NetworkPolicy (Traffic Control):
Control access. For example, only allow the frontend to access the backend.
Example YAML:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: policy-backend
spec:
podSelector:
matchLabels:
app: backend
ingress:
– from:
– podSelector:
matchLabels:
app: frontend
Summary:
Pod: A house.
Service: An address plate.
Ingress: A doorman.
NetworkPolicy: A gate with a password.
Namespaces
Namespaces in Kubernetes act as “partitions” within the cluster. They help organize and isolate resources. Think of them as folders in a file system: you can separate environments (production, staging, development) or teams (frontend, backend).
Why Use Namespaces?
Organization: Separate resources for environments or teams.
Isolation: Restrict access to resources using RBAC and NetworkPolicies (covered in part 3).
Quotas: Set limits on CPU, memory, or specific resources.
Default Namespaces in Kubernetes:
default: Where resources go if no namespace is specified.
kube-system: Internal Kubernetes components (e.g., DNS).
kube-public: Data accessible to everyone.
How to Create a Namespace:
Using the Command Line (kubectl):
kubectl create namespace my-namespace
Using YAML:
apiVersion: v1
kind: Namespace
metadata:
name: my-namespace
Apply it with:
kubectl apply -f namespace.yaml
Using Namespaces:
Create Resources in a Specific Namespace: Add -n <namespace> to the command:
kubectl create deployment nginx –image=nginx -n my-namespace
Specify Namespace in YAML:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
namespace: my-namespace
spec:
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
– name: nginx
image: nginx
Change the Default Namespace: Avoid typing -n repeatedly:
kubectl config set-context –current –namespace=my-namespace
Tip: Resource Quotas in Namespaces
You can limit resource usage within a namespace using ResourceQuota.
Example: Limit CPU and Memory Usage
apiVersion: v1
kind: ResourceQuota
metadata:
name: quotas
namespace: my-namespace
spec:
hard:
requests.cpu: “2”
requests.memory: 4Gi
limits.cpu: “4”
limits.memory: 8Gi
Apply it with:
kubectl apply -f resourcequota.yaml
Services
In Kubernetes, Services are used to expose a set of Pods for communication within or outside the cluster. They provide an abstraction layer, ensuring applications can locate Pods even as their IPs change.
Why Use Services?
Service Discovery: Enable locating Pods without relying on dynamic IPs.
Load Balancing: Distribute traffic among associated Pods.
External Connectivity: Expose applications to the outside world.
Types of Services:
ClusterIP (Default):
Exposes the service within the cluster.
Used for communication between Pods.
NodePort:
Opens a fixed port on each node for external access.
Example: Local development or testing.
LoadBalancer:
Creates a public IP (requires cloud provider support).
Ideal for production environments.
ExternalName:
Redirects traffic to an external DNS name.
Example: Connecting to external APIs.
Creating a Service:
ClusterIP (Internal Communication):
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app: my-app
ports:
– protocol: TCP
port: 80
targetPort: 8080
port: Port exposed by the Service.
targetPort: Port of the Pod.
selector: Defines the Pods associated with the Service.
Apply it with:
kubectl apply -f service-clusterip.yaml
NodePort (External Access):
apiVersion: v1
kind: Service
metadata:
name: my-nodeport
spec:
type: NodePort
selector:
app: my-app
ports:
– protocol: TCP
port: 80
targetPort: 8080
nodePort: 30007
Access it via:
http://<Node_IP>:30007
LoadBalancer (Public IP):
apiVersion: v1
kind: Service
metadata:
name: my-loadbalancer
spec:
type: LoadBalancer
selector:
app: my-app
ports:
– protocol: TCP
port: 80
targetPort: 8080
Requires a cloud provider (e.g., AWS, GCP, Azure) to automatically create a public IP.
ExternalName (External DNS):
apiVersion: v1
kind: Service
metadata:
name: my-externalname
spec:
type: ExternalName
externalName: api.example.com
Access the service at:
api.example.com
Check Services:
Use the command:
kubectl get services
Summary:
ClusterIP: Internal communication.
NodePort: Fixed external access.
LoadBalancer: Public IP for production.
ExternalName: Redirects to an external DNS.
With Services, you can connect components seamlessly and scalably in Kubernetes. Ready to practice and start using them?
Consuming a ClusterIP Service
To consume a ClusterIP Service, ensure that the Pods consuming the service are in the same cluster (or namespace, depending on the context). Here’s a practical example:
Scenario:
We have a backend application running in Pods, exposed by a ClusterIP Service called backend-service.
A frontend application consumes this service.
Backend Configuration:
Backend Deployment:
apiVersion: apps/v1
kind: Deployment
metadata:
name: backend
spec:
replicas: 2
selector:
matchLabels:
app: backend
template:
metadata:
labels:
app: backend
spec:
containers:
– name: backend
image: hashicorp/http-echo
args:
– “-text=Hello from Backend!”
ports:
– containerPort: 8080
ClusterIP Service:
apiVersion: v1
kind: Service
metadata:
name: backend-service
spec:
selector:
app: backend
ports:
– protocol: TCP
port: 80
targetPort: 8080
Frontend Configuration:
Frontend Deployment:
apiVersion: apps/v1
kind: Deployment
metadata:
name: frontend
spec:
replicas: 1
selector:
matchLabels:
app: frontend
template:
metadata:
labels:
app: frontend
spec:
containers:
– name: frontend
image: curlimages/curl
command: [ “sh”, “-c”, “while true; do curl http://backend-service; sleep 5; done” ]
Steps to Deploy:
Apply the manifests:
kubectl apply -f backend-deployment.yaml
kubectl apply -f backend-service.yaml
kubectl apply -f frontend-deployment.yaml
Verify the Pods and Services:
kubectl get pods
kubectl get services
Check the frontend (consumer) logs:
kubectl logs -l app=frontend -f
You will see output like:
Hello from Backend!
Hello from Backend!
Hello from Backend!
How It Works:
The backend-service is a ClusterIP Service, creating an internal IP accessible only within the cluster.
The frontend makes calls to http://backend-service (internal DNS generated by Kubernetes).
The ClusterIP Service routes traffic to the backend Pods.
Tip:
Use Kubernetes’ internal DNS to reference the service:
The service name (backend-service) automatically works as a DNS name within the cluster, allowing seamless communication without worrying about Pod IPs.
Consuming a NodePort Service
When using a NodePort Service, the service exposes a fixed port on each node in the cluster, enabling external access via any node’s IP and the designated port.
Scenario:
A backend service is exposed as a NodePort Service.
The service is accessed from outside the cluster using a node’s IP.
Backend Configuration:
Backend Deployment:
apiVersion: apps/v1
kind: Deployment
metadata:
name: backend
spec:
replicas: 2
selector:
matchLabels:
app: backend
template:
metadata:
labels:
app: backend
spec:
containers:
– name: backend
image: hashicorp/http-echo
args:
– “-text=Hello from Backend (NodePort)!”
ports:
– containerPort: 8080
NodePort Service:
apiVersion: v1
kind: Service
metadata:
name: backend-service-nodeport
spec:
type: NodePort
selector:
app: backend
ports:
– protocol: TCP
port: 80
targetPort: 8080
nodePort: 30007
Steps to Deploy:
Apply the manifests:
kubectl apply -f backend-deployment.yaml
kubectl apply -f backend-service-nodeport.yaml
Check the service:
kubectl get service backend-service-nodeport
Example output:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
backend-service-nodeport NodePort 10.96.0.234 <none> 80:30007/TCP 5m
Here, 30007 is the open port on all nodes.
Find a node’s IP:
kubectl get nodes -o wide
This will display the nodes’ external/internal IPs.
Consume the service:
Use a browser, cURL, or an HTTP tool to access:
http://<NODE_IP>:30007
Example using cURL:
curl http://<NODE_IP>:30007
Expected output:
Hello from Backend (NodePort)!
Testing with Minikube:
If using Minikube, get the node’s IP with:
minikube ip
Then access:
http://<Minikube_IP>:30007
How It Works:
A NodePort Service creates a fixed port (nodePort) on all cluster nodes.
Any request to http://<Node_IP>:30007 is routed to the backend Pods.
Kubernetes automatically load balances traffic among the Pods.
Tip:
Avoid NodePort in production; use LoadBalancer or Ingress for external exposure.
Use NodePort for development or testing in local environments or without cloud providers.
Liveness Probes
Liveness Probes are how Kubernetes checks if your application is still “alive” and functioning. If the probe fails, the container is restarted. This is useful when your application crashes or enters a state where it cannot recover by itself.
How It Works:
You define a rule for Kubernetes to check the container’s state. There are three main types of probes:
HTTP: Makes an HTTP request to an endpoint.
Command: Executes a command inside the container.
TCP: Checks if it can connect to a specific port.
Basic Example:
Liveness Probe HTTP
apiVersion: apps/v1
kind: Deployment
metadata:
name: app-with-liveness
spec:
replicas: 1
selector:
matchLabels:
app: example
template:
metadata:
labels:
app: example
spec:
containers:
– name: app
image: nginx
livenessProbe:
httpGet:
path: /
port: 80
initialDelaySeconds: 5
periodSeconds: 10
Explanation:
httpGet: Makes an HTTP request to the / path on port 80.
initialDelaySeconds: Waits for 5 seconds before starting the checks.
periodSeconds: Checks every 10 seconds.
Liveness Probe with Command
apiVersion: apps/v1
kind: Deployment
metadata:
name: app-with-liveness-command
spec:
replicas: 1
selector:
matchLabels:
app: example
template:
metadata:
labels:
app: example
spec:
containers:
– name: app
image: busybox
command:
– sh
– -c
– echo “Starting app”; sleep 1000
livenessProbe:
exec:
command:
– cat
– /tmp/healthy
initialDelaySeconds: 5
periodSeconds: 10
Explanation:
The container must create the /tmp/healthy file to be considered “alive.”
If the file disappears, the probe fails, and Kubernetes will restart the container.
Liveness Probe TCP
apiVersion: apps/v1
kind: Deployment
metadata:
name: app-with-liveness-tcp
spec:
replicas: 1
selector:
matchLabels:
app: example
template:
metadata:
labels:
app: example
spec:
containers:
– name: app
image: nginx
livenessProbe:
tcpSocket:
port: 80
initialDelaySeconds: 5
periodSeconds: 10
Explanation:
Verifies if port 80 is open and accepting connections.
Testing:
Apply the YAML:
kubectl apply -f <file.yaml>
Check the status of the Pods:
kubectl get pods
Check the events:
kubectl describe pod <pod-name>
If the Liveness Probe fails, you will see something like:
Warning Unhealthy Liveness probe failed: HTTP probe failed with statuscode: 500
When to Use:
App Crashes: If your app can freeze, use liveness probes to automatically restart it.
External Dependencies: If your app relies on something external and might enter a “broken” state.
Quick Tip:
Combine liveness probes with readiness probes to ensure the app only receives traffic when it’s truly ready.
Resource Management
Managing resources in Kubernetes is essentially about ensuring your Pods do not overconsume (or run out of) CPU and memory. You control this by setting limits and requests directly on the containers.
Why Is This Important?
Avoid Conflicts: If a container uses too much CPU/memory, it could crash other containers or even the node.
Ensure Performance: Reserve what the application needs to run smoothly.
Load Balancing: Kubernetes uses this information to intelligently distribute Pods across nodes.
How It Works:
Requests: The minimum amount of CPU/memory that the container needs. Kubernetes uses this to schedule the Pod on a node with enough capacity.
Limits: The maximum amount of CPU/memory the container can use. If it exceeds the limit, the container will be throttled (for CPU) or even terminated (in case of memory).
Simple Example:
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
– name: my-app
image: nginx
resources:
requests:
memory: “128Mi”
cpu: “250m”
limits:
memory: “256Mi”
cpu: “500m”
What Does This Mean?
The container requires 128Mi of memory and 250m (0.25 vCPU) to start.
At most, it can use 256Mi of memory and 500m (0.5 vCPU).
If it tries to use more memory, the container will be terminated due to OOM (Out of Memory).
If it tries to use more CPU, it will be throttled.
Testing Resource Usage:
Run a container that uses CPU:
apiVersion: v1
kind: Pod
metadata:
name: cpu-tester
spec:
containers:
– name: cpu-tester
image: busybox
command: [“sh”, “-c”, “while true; do :; done”]
resources:
limits:
cpu: “100m”
Check the usage:
kubectl top pod
You will see it is limited to around 10% of a CPU core.
Tips:
Always set both requests and limits on containers.
For critical apps, use Pod Priority and Preemption to ensure they run.
Monitor the cluster with tools like Metrics Server, Prometheus, or Grafana.
Summary:
Managing resources in Kubernetes is about ensuring everyone gets what they need without anyone taking more than they should.
Volumes
Volumes in Kubernetes solve a simple problem: the lifecycle of containers. When a container restarts, its data is lost, but sometimes you need to store something for longer periods. A Volume connects persistent or shared storage to your Pods.
Types of Volumes
emptyDir
A blank directory created when the Pod is started.
Everything is deleted when the Pod is deleted.
Good for temporary storage between containers within the same Pod.
volumes:
– name: my-volume
emptyDir: {}
hostPath
Uses a directory on the node where the Pod is running.
Can be risky in production because it depends on the node.
volumes:
– name: my-volume
hostPath:
path: /data
persistentVolumeClaim (PVC)
Links the Pod to persistent storage (e.g., cloud disks).
Survives even if the Pod or cluster restarts.
volumes:
– name: my-volume
persistentVolumeClaim:
claimName: my-pvc
configMap and secret
We’ll discuss in Part 3, but it’s used to store configurations and sensitive data.
nfs
Connects your Pod to an NFS server.
Useful for sharing data between Pods.
volumes:
– name: my-nfs
nfs:
server: 192.168.1.1
path: /export
Complete Example: emptyDir
apiVersion: v1
kind: Pod
metadata:
name: pod-with-volume
spec:
containers:
– name: app
image: busybox
command: [“sh”, “-c”, “echo ‘data’ > /data/test.txt && sleep 3600”]
volumeMounts:
– name: my-volume
mountPath: /data
volumes:
– name: my-volume
emptyDir: {}
What Happens?
The /data directory in the container is linked to the emptyDir volume.
Any file created there is shared between containers within the same Pod.
Example with PVC
Create a PersistentVolume (PV):
apiVersion: v1
kind: PersistentVolume
metadata:
name: my-pv
spec:
capacity:
storage: 1Gi
accessModes:
– ReadWriteOnce
hostPath:
path: /mnt/data
Create a PersistentVolumeClaim (PVC):
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: my-pvc
spec:
accessModes:
– ReadWriteOnce
resources:
requests:
storage: 500Mi
Use the PVC in the Pod:
apiVersion: v1
kind: Pod
metadata:
name: pod-with-pvc
spec:
containers:
– name: app
image: nginx
volumeMounts:
– name: my-volume
mountPath: /data
volumes:
– name: my-volume
persistentVolumeClaim:
claimName: my-pvc
Practical Tips
Persistent Storage: Use PVC and PV for important data (e.g., databases, logs).
Temporary Files: Use emptyDir.
Security: Store sensitive information with secrets.
Caution with hostPath: Avoid using it in production, as it ties your app to a specific node.
In Summary: Volumes are Kubernetes’ flexible way of handling storage. You just choose the right type for your problem and go ahead!
This concludes Part 2 of our Kubernetes series. Was it clear? Don’t worry if you didn’t understand everything completely. The most important thing is to practice the examples to gain a deeper understanding. Thank you for reading!