
🇬🇧How to Go Back in Time and Access Historical Versions of Your Tables
🇧🇷–para ler este artigo em português clique aqui
Have you ever imagined being able to go back in time and access the modification history of a table? This is possible with the Time Travel functionality of Delta Lake.
What is Delta Lake?
Delta Lake is an open-source storage layer that enhances data lakes by adding ACID transaction capabilities (Atomicity, Consistency, Isolation, and Durability). It integrates with Apache Spark, offering reliability and performance to handle large volumes of data. To learn more about how to implement Delta Lake in your Spark jobs, access the documentation.
But briefly, to configure Delta Lake in your Spark session, I will present an example below:
spark = SparkSession.builder \
.appName("Delta Lake Example") \
.config("spark.jars.packages", "io.delta:delta-core_2.12:1.0.0") \
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") \
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog") \
.config("spark.databricks.delta.retentionDurationCheck.enabled", "true") \
.config("spark.databricks.delta.retentionDurationCheck.retentionDuration", "30 days") \
.getOrCreate()
This is an example of a Spark session with the Delta Lake configuration added. I will explain each of these configurations so that you understand the relationship between Spark, Delta Lake, and Time Travel, our table time machine.
spark.jars.packages: This configuration defines the JAR packages to be included in the Spark environment and specifies the Maven dependency for Delta Lake.spark.sql.extensions: Defines the Spark SQL extensions that will be loaded when starting a Spark session.spark.sql.catalog.spark_catalog: Defines the catalog used to store table and view metadata in Spark.spark.databricks.delta.retentionDurationCheck.enabled: Controls whether retention duration checking is enabled in Delta Lake.spark.databricks.delta.retentionDurationCheck.retentionDuration: Sets the retention duration for data versions in Delta Lake.
Keeping in mind what each configuration is for, notice that our time machine is being configured in spark.databricks.delta.retentionDurationCheck.retentionDuration, where we define the number of days that will be stored and available for query and recovery. In the example presented, I set a retention time of 30 days, so my Delta table lets me travel back up to 30 days.
After configuring your Spark session, simply write your table in “delta” format:
df.write.format("delta").mode("overwrite").save(delta_path)
Time Travel:
Time Travel in Delta Lake allows table users to return to previous versions and access the modification history. This is useful for data auditing, debugging, and table correction.
To access the history of a Delta table using Python, I will present some code examples.
Importing:
from delta.tables import DeltaTable
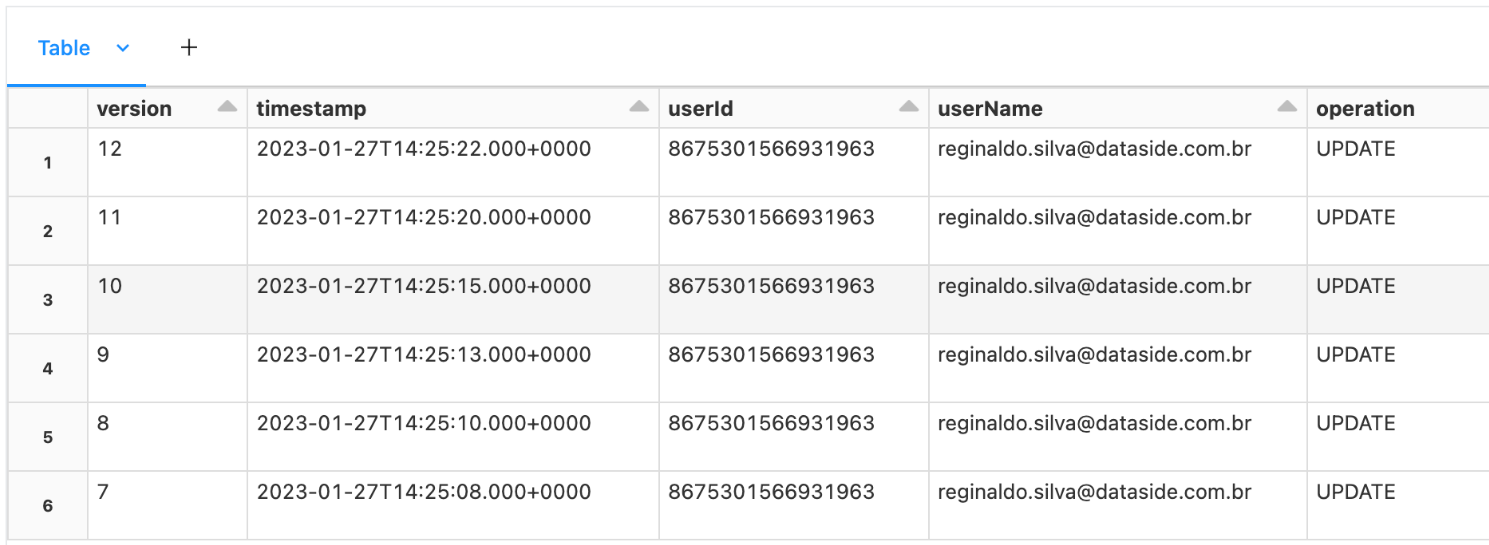
Displaying table version history:
deltaTable = DeltaTable.forPath(ss.spark, "path/to/table")
fullHistoryDF = deltaTable.history()
This code will display the history of saved versions with identification and change numbers.
Restoring a table version:
deltaTable.restoreToVersion(4254)
In parentheses, you should add the version number you want to restore.
ATTENTION!
Last but not least, keep in mind that the retention time will use capacity and storage resources to keep the history of your tables. This can impact storage costs and query performance.
This is a summary of how time travel works using the Time Travel function of Delta Lake. You can delve deeper into the topic and view other useful command lines of the tool. I hope this has helped you understand a little more about how this amazing functionality works.