
🇧🇷 Kubernetes: Parte 1
🇬🇧 To read this article in English click here
Nesta série de artigos, vamos explorar o Kubernetes em 3 partes. O Kubernetes é uma ferramenta extremamente poderosa, mas que pode se tornar complexa se não for explicada de maneira clara. Para abordar o tema de forma completa e acessível, decidi criar esta série, sendo esta a primeira parte. Aqui, pretendo explicar o que é o Kubernetes, como realizar sua configuração inicial, seus fundamentos e conceitos principais, além de apresentar os componentes essenciais. Esse é apenas o começo da jornada. Vamos começar?
Kubernetes Parte 1
O que é o kubernetes?
Kubernetes é tipo o maestro de uma orquestra de servidores. Ele é responsável por gerenciar e coordenar aplicativos que estão rodando em contêineres, como o Docker. Imagine que você tem vários serviços e aplicativos espalhados por diferentes máquinas, e quer garantir que eles estejam sempre funcionando, que novos sejam adicionados quando necessário, e que os antigos sejam atualizados ou removidos sem bagunça. Kubernetes faz isso pra você.
Ele distribui automaticamente as tarefas entre os servidores, garante que tudo esteja rodando como deveria e até resolve problemas sozinho, como reiniciar um serviço que deu pau. Além disso, ele facilita coisas como escalar aplicações (colocar mais “força” onde precisa) e fazer deploys de novas versões sem derrubar tudo. É como ter um super assistente para lidar com toda a infraestrutura, deixando você mais focado no que realmente importa.
Conceito de imutabilidade kubernetes:
Imutabilidade no Kubernetes é simples: em vez de mexer em algo que já existe, ele cria uma nova versão. Por exemplo, se você quer atualizar um contêiner em um Deployment, o Kubernetes não altera o que está rodando. Ele cria novos Pods com a configuração atualizada e, quando esses novos estão prontos, substitui os antigos.
Isso garante que você sempre tem um “registro de versões”. Se algo der errado, dá para voltar atrás facilmente. É como se o Kubernetes fosse construindo versões novas das suas aplicações sem bagunçar o que já está rodando, mantendo tudo organizado e previsível.
Na prática, a imutabilidade no Kubernetes funciona assim:
Definição do estado desejado: Você cria ou altera um arquivo YAML(vamos falar dele na parte 2) com as configurações do recurso que quer rodar (tipo um Deployment). Esse arquivo descreve tudo: quantos réplicas você quer, qual imagem usar, etc.
Aplicação da configuração: Quando você manda esse arquivo para o cluster, o Kubernetes compara o que está no arquivo com o que já está rodando no cluster.
Atualização imutável: Se algo mudou no arquivo (tipo uma nova versão da imagem do contêiner), o Kubernetes começa a criar novos Pods com essa configuração atualizada. Os Pods antigos não são editados; eles continuam rodando até os novos ficarem prontos.
Substituição gradual: Depois que os novos Pods estão saudáveis e prontos, o Kubernetes vai desligando os Pods antigos. Isso é chamado de rolling update, e garante que não fique tudo fora do ar de uma vez.
Rollback fácil: Se a nova configuração der problema, você pode reverter rapidamente para a versão anterior. Como cada alteração cria algo novo, você sempre tem um “backup” do estado anterior.
A ideia é que tudo que roda no Kubernetes seja descartável e substituível. Nada é “ajustado” manualmente, tudo é recriado com base no que você descreveu nos arquivos. É isso que garante consistência e previsibilidade no ambiente.
Um pouco de fundamento:
No Kubernetes, você tem duas formas de fazer as coisas: comandos imperativos e configurações declarativas. A diferença é simples: uma é mais direta, tipo “faça isso agora”, e a outra é mais planejada, tipo “aqui está o que quero, dê seu jeito”.
Comandos Imperativos
Esses são os comandos que você roda direto no terminal para fazer algo na hora. É rápido, direto ao ponto, mas não deixa “rastro” do que foi feito.
Exemplo:
kubectl create deployment my-app –image=nginx
Aqui você está mandando o Kubernetes criar o Deployment do nginx. Fácil e rápido, mas se precisar repetir isso amanhã, vai ter que lembrar ou anotar o comando.
Vantagens:
- Ótimo para testes rápidos.
- Não precisa de arquivos YAML.
Desvantagens:
- Difícil de manter controle do que foi criado.
- Não é reutilizável.
Configurações Declarativas
Aqui você escreve um arquivo YAML que descreve o que quer no cluster. Em vez de mandar “faça isso agora”, você fala “esse é o estado que quero”, e o Kubernetes ajusta tudo pra chegar lá.
O código abaixo será explicado futuramente, não se prenda a ele
Exemplo de YAML:
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-app
spec:
replicas: 3
selector:
matchLabels:
app: my-app
template:
metadata:
labels:
app: my-app
spec:
containers:
- name: nginx
image: nginxDepois, aplica o arquivo com:
kubectl apply -f deployment.yaml
Vantagens:
- Fácil de versionar no Git.
- Reutilizável e mais organizado.
Desvantagens:
- Demanda mais tempo no começo.
- Pode parecer mais complicado para quem está começando.
Resumo
- Imperativo: “Faz agora!” (rápido, mas desorganizado).
- Declarativo: “Aqui está o plano, segue ele!” (organizado, ideal para produção).
No dia a dia, imperativo é bom pra coisas rápidas, mas declarativo é o caminho certo pra quem quer escalar e ter controle.
Kubectl:
O kubectl é sua ferramenta principal para tudo no Kubernetes. Desde criar recursos até resolver problemas, ele tem um comando pra tudo. É como um canivete suíço: com ele, você faz tudo que precisa no cluster.
Ele é a ferramenta de linha de comando que você usa para gerenciar praticamente tudo no cluster. Com o kubectl, você pode criar, listar, atualizar e deletar recursos do Kubernetes, além de monitorar o que está acontecendo.
Estrutura básica do comando kubectl
A sintaxe geral é:
kubectl [comando] [tipo-de-recurso] [nome-do-recurso] [flags]
Exemplos:
Criar um Deployment:
kubectl create deployment meu-app –image=nginx
- create → Diz que você quer criar algo.
- deployment → O tipo de recurso que você quer criar.
- meu-app → Nome que você está dando ao recurso.
- –image=nginx → Especifica a imagem do contêiner que será usada.
Listar recursos no cluster:
kubectl get pods
- get → Pede para listar recursos.
- pods → O tipo de recurso que você quer ver.
Detalhes sobre um recurso específico:
kubectl describe pod meu-pod
- describe → Mostra informações detalhadas sobre o recurso.
- meu-pod → Nome do Pod que você quer inspecionar.
Deletar um recurso:
kubectl delete pod meu-pod
- delete → Remove o recurso especificado.
- meu-pod → Nome do recurso a ser deletado.
Aplicar configurações de um arquivo YAML:
kubectl apply -f deployment.yaml
- apply → Aplica a configuração declarada no arquivo.
- -f → Indica o caminho do arquivo YAML.
Vamos ver os comandos na prática mais à frente, porém, caso queira se adiantar, o Kubernetes tem uma documentação completa sobre a command-line tool.
https://kubernetes.io/docs/reference/kubectl
Componentes do kubernetes:
Control Plane:
O control plane é o cérebro do Kubernetes. Ele é o cara que decide o que acontece no cluster e garante que tudo funcione como você pediu. Basicamente, ele gerencia o estado do cluster e os recursos que estão rodando.
Como ele trabalha:
Recebe ordens: Quando você aplica um YAML (vamos falar dele mais a frente mas o comando é esse: kubectl apply -f deploy.yaml), o control plane pega esse pedido e registra no sistema como o estado desejado.
Pensa no plano: Ele compara o que você pediu (estado desejado) com o que realmente está rodando (estado atual). Se estiver diferente, ele começa a corrigir.
Faz as coisas acontecerem: Ele manda ordens para os nós (máquinas onde os Pods rodam) para criar, deletar ou ajustar recursos até que tudo esteja do jeito que você quer.
Componentes importantes:
- API Server: É o cara que escuta seus comandos (kubectl) e conecta tudo.
- Scheduler: Decide em qual nó cada Pod vai rodar.
- Controller Manager: Cuida de processos automáticos, como criar novos Pods se algum der pau.
- etcd: É o banco de dados que guarda todas as informações do cluster (configurações, estado, etc.).
Em resumo:
O control plane fica cuidando do cluster 24/7. Ele ouve o que você quer, vê o que precisa ser ajustado e faz tudo funcionar. Se algo der errado, ele tenta arrumar sozinho. É o chefe que nunca dorme.
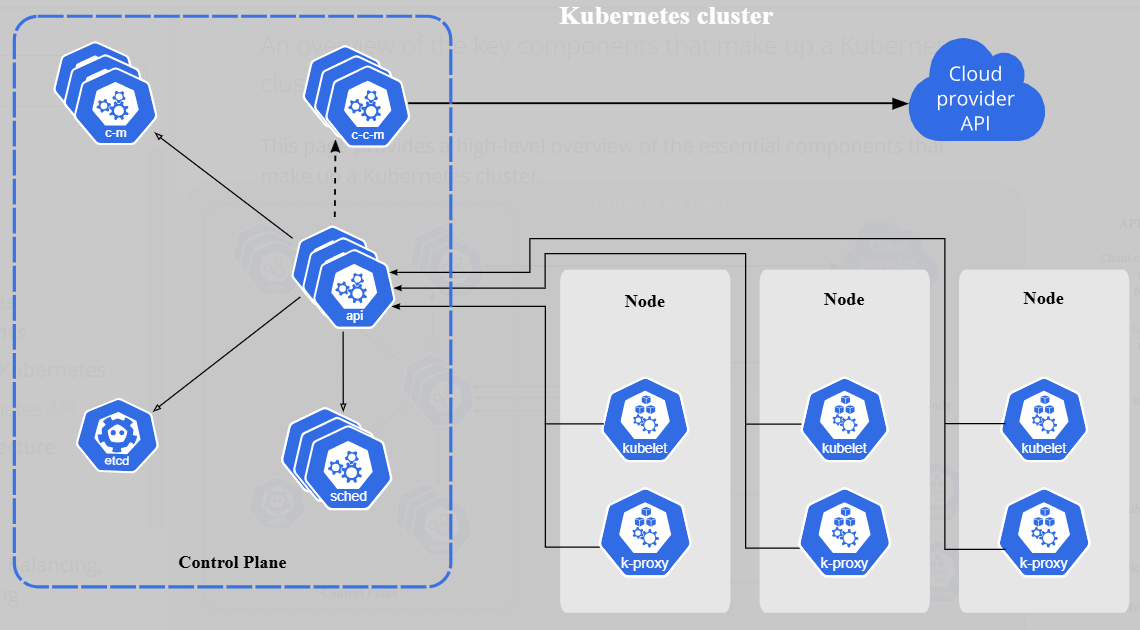
não se assuste com essa imagem, em breve você entenderá.
Conceito de recursos pods
O Pod é a menor unidade do Kubernetes. É tipo o “caixinha” onde seus aplicativos vivem dentro do cluster. Ele não é só um container, mas sim uma camada que envolve um ou mais containers e garante que eles funcionem juntos como uma unidade.
Como funciona na prática?
- 1 Pod = 1 ou mais containers.
Na maioria dos casos, você usa só um container por Pod. Mas, se os containers precisam trabalhar juntos, tipo um app que precisa de um sidecar (ex.: um log collector), você coloca mais de um container dentro do mesmo Pod. - Compartilham o mesmo IP e porta:
Todos os containers no Pod dividem a mesma rede, então eles se comunicam por localhost. Por exemplo, o container A pode falar com o container B sem precisar expor portas externamente. - Recursos compartilhados:
- Volumes: Se precisar guardar dados ou compartilhar arquivos entre containers no Pod, você usa volumes.
- Configs: Pode usar ConfigMaps ou Secrets para passar configurações sensíveis.
Recursos dos Pods:
O Kubernetes dá ferramentas para você controlar o uso de recursos (CPU, memória, etc.) dentro dos Pods.
Requests:
É o mínimo que o Pod precisa para rodar. Quando você define um request, o Kubernetes garante que o Node tenha esses recursos disponíveis antes de alocar o Pod.
Exemplo:
resources:
requests:
memory: “256Mi”
cpu: “500m”
Limits:
É o máximo que o Pod pode usar. Se o Pod tentar consumir mais do que isso, o Kubernetes pode limitar ou até matar ele (no caso de excesso de memória).
Exemplo:
resources:
limits:
memory: “512Mi”
cpu: “1”
Quando um Pod é criado?
Sempre que você manda rodar algo no Kubernetes, o que realmente é criado no cluster é um Pod. Por exemplo:
- Um Deployment? Cria Pods para os containers.
- Um Job? Cria Pods para rodar a tarefa.
O que acontece quando um Pod morre?
Pod morreu? Adeus! O Kubernetes não revive Pods diretamente. Ele cria novos se for configurado para isso. Por exemplo:
- Com um Deployment ou ReplicaSet, novos Pods são recriados automaticamente.
- Um Pod sozinho sem controlador? Morreu, acabou.
Resumo:
Os Pods são o alicerce do Kubernetes. Eles encapsulam containers e gerenciam como esses containers rodam, compartilham recursos e se comunicam. Se você entende Pods, entende o básico de como os aplicativos rodam no Kubernetes.
Kube-apiserver:
O kube-apiserver é como uma porta de entrada do Kubernetes. Ele é quem recebe todos os comandos e pedidos, seja do kubectl, de aplicações externas ou de outros componentes do próprio cluster.
O que ele faz?
Recebe comandos: Sempre que você faz algo no Kubernetes, como criar um Pod ou aplicar um Deployment, é o kube-apiserver que recebe essa requisição.
Checa e valida: Ele dá uma olhada no que você mandou e valida se está tudo certo. Por exemplo, se você tentou criar um Pod com configurações erradas, ele vai te avisar.
Grava no etcd: Depois de validar, ele salva os detalhes do recurso no etcd (o banco de dados do cluster). Esse é o lugar onde o Kubernetes guarda todas as informações.
Faz o meio de campo: Ele avisa os outros componentes do cluster (tipo o scheduler e os controllers) sobre as mudanças para que eles tomem as próximas ações.
Por que é importante?
Sem o kube-apiserver, o Kubernetes não funciona. Ele é como um intermediário que traduz o que você quer e garante que todo o cluster saiba disso. É como o balcão de informações de um shopping: todo mundo passa por ele para pedir alguma coisa.
Em resumo, o kube-apiserver é o cara que conecta você e o Kubernetes, organizando tudo para garantir que o cluster funcione direitinho.
cloud-controller-maneger:
O Cloud Controller Manager é um dos componentes do Control Plane do Kubernetes que conecta o cluster com serviços específicos de provedores de nuvem, como AWS, GCP ou Azure. Ele basicamente traduz as interações do Kubernetes com a infraestrutura da nuvem.
O que ele faz na prática?
Ele gerencia recursos que estão fora do cluster, mas que são necessários para o Kubernetes funcionar, como balanceadores de carga, volumes de armazenamento e endereços IP públicos. Em outras palavras, ele é o “cara da ponte” entre o Kubernetes e a nuvem.
Como funciona?
O Cloud Controller Manager tem vários controladores internos que tratam diferentes aspectos. Cada controlador é responsável por uma tarefa específica, como:
Node Controller
- Garante que os nós (VMs) registrados no cluster estão funcionando. Se uma VM for removida na nuvem, ele limpa a referência no Kubernetes.
Route Controller
- Configura rotas de rede entre os nós no ambiente da nuvem para que os Pods possam se comunicar.
Service Controller
- Gerencia balanceadores de carga da nuvem para serviços do tipo LoadBalancer. Por exemplo, se você expõe um serviço no Kubernetes, ele cria e configura o Load Balancer na nuvem automaticamente.
Volume Controller
- Cuida de provisionar e conectar volumes de armazenamento (tipo EBS na AWS, Persistent Disks no GCP, etc.) aos Pods.
Quando o Cloud Controller Manager entra em ação?
Sempre que você usa algo no Kubernetes que depende da infraestrutura da nuvem. Por exemplo:
- Cria um Service com type: LoadBalancer → ele configura o Load Balancer na sua nuvem.
- Adiciona um PVC (Persistent Volume Claim) → ele provisiona o disco automaticamente no backend da nuvem.
- Apaga um nó que não responde → ele checa se a VM foi removida na nuvem e limpa isso do cluster.
Ele é obrigatório?
Se você está rodando Kubernetes em bare-metal (ou seja, sem nuvem), o Cloud Controller Manager não faz nada, porque não tem integração com provedores de nuvem. Mas se o cluster estiver em AWS, Azure, GCP, etc., ele é essencial para automatizar as integrações.
Resumo:
O Cloud Controller Manager é tipo o “tradutor oficial” entre Kubernetes e nuvem. Ele cuida das coisas fora do cluster, como balanceadores e volumes, para que você não precise configurar tudo manualmente. É uma peça importante para clusters rodando em ambientes de nuvem.
controller-menager:
O Controller Manager é o “gerente multitarefa” do Kubernetes. Ele é o cara responsável por rodar os controladores que cuidam de várias funções dentro do cluster. Cada controlador resolve um problema específico, e o Controller Manager gerencia todos eles de forma centralizada. É um dos componentes do Control Plane e essencial para manter o cluster funcionando do jeito que você espera.
O que é um controlador?
Um controlador é basicamente um loop que fica monitorando o estado atual de algum recurso no cluster e tenta ajustá-lo para o estado desejado. No Kubernetes, tudo é baseado na ideia de estado desejado versus estado atual.
Exemplo:
Você quer 3 réplicas de um Pod rodando (estado desejado). Se um desses Pods falhar, o controlador vai perceber que só tem 2 Pods rodando (estado atual) e criar mais um para alinhar os dois estados.
O que o Controller Manager faz?
Ele é como o “organizador de loops”, rodando vários controladores ao mesmo tempo. Alguns dos principais controladores que ele gerencia são:
Replication Controller
- Garante que o número certo de réplicas de um Pod esteja rodando.
Node Controller
- Verifica se os nós (VMs) do cluster estão ativos. Se um nó ficar offline, ele marca como “NotReady”.
Endpoints Controller
- Atualiza os objetos de Endpoints para conectar serviços com os Pods certos.
Service Account & Token Controllers
- Gerencia contas de serviço e os tokens necessários para autenticação dentro do cluster.
Job Controller
- Garante que Jobs (tarefas únicas) rodem até completarem.
Persistent Volume Controller
- Gerencia o ciclo de vida de volumes persistentes, conectando PVCs (Persistent Volume Claims) aos PVs (Persistent Volumes).
Como ele funciona?
- Ele roda como um processo único no Control Plane.
- Todos os controladores estão embutidos nele.
- Fica constantemente olhando o estado atual do cluster (via etcd) e tentando alinhar com o que você declarou nos manifests YAML.
Quando o Controller Manager entra em ação?
Toda vez que algo muda no cluster. Exemplos:
- Você apaga um Pod manualmente → O Replication Controller recria.
- Um nó do cluster cai → O Node Controller marca ele como indisponível.
- Você cria um PVC → O Persistent Volume Controller provisiona um volume, se possível.
Resumo:
O Controller Manager é o “faz tudo” do Kubernetes. Ele não cria nada diretamente, mas comanda os controladores que fazem. Se um recurso precisa de ajuste, ele é quem garante que as mudanças sejam feitas. Sem ele, o cluster seria um caos, porque ninguém estaria cuidando do estado dos recursos.
etcd- cluster persistence storage:
O etcd é o coração do Kubernetes. Ele é um banco de dados chave-valor rápido e distribuído que guarda todo o estado do cluster. Sem ele, o Kubernetes não saberia o que está rodando, quais são os recursos ou como alinhar o que você quer com o que está acontecendo no cluster.
O que é o etcd na prática?
Pensa nele como uma agenda superorganizada: tudo que acontece ou precisa acontecer no Kubernetes está anotado lá. Desde quais Pods devem estar rodando, até detalhes como ConfigMaps, Secrets e o status dos Nodes.
Por que armazenamento persistente é importante?
O etcd precisa de persistência porque:
Ele mantém o estado atual do cluster. Se o etcd apagar, o Kubernetes esquece de tudo.
É um componente crítico para a recuperação de desastres. Se o cluster quebrar, o backup do etcd é o que traz tudo de volta.
Onde e como armazenar o etcd?
- Local: Um disco rápido no servidor onde o etcd está rodando.
- Nuvem: Storage persistente da nuvem, como EBS na AWS ou Persistent Disks no GCP.
- Clusters de etcd: Para alta disponibilidade, você roda um cluster etcd com 3 ou 5 instâncias. Isso distribui os dados, evita perda total em caso de falha de um nó e mantém o etcd funcionando.
Como o etcd trabalha no Kubernetes?
- O kube-apiserver é o único que fala com o etcd diretamente.
- Ele lê e escreve no etcd para guardar e buscar o estado do cluster.
- Exemplos de dados guardados:
- Especificações de Deployments, Pods, Services.
- Segredos e configurações.
- Status de cada recurso.
Dica de ouro: Backups!
Como o etcd é a “memória” do Kubernetes, fazer backup dele é obrigatório. Sem backup, você perde tudo. Para clusters grandes ou em produção, use ferramentas que automatizam isso, como o etcdctl snapshot.
Resumo:
O etcd é essencial. É onde o Kubernetes guarda tudo que importa. Sem um armazenamento persistente confiável, você está arriscando perder o estado do cluster inteiro. Portanto, capriche na configuração e tenha backups sempre atualizados!
kube-proxy
O kube-proxy é como o “roteador” do Kubernetes. Ele gerencia as regras de rede no cluster, garantindo que os Serviços (Services) consigam distribuir tráfego para os Pods certos. Basicamente, ele é quem faz a mágica de conexão interna no cluster, garantindo que os pedidos cheguem onde precisam.
O que o kube-proxy faz?
Distribui o tráfego:
Quando você cria um Service, ele garante que o tráfego seja encaminhado para os Pods associados a esse Service.
Gerencia regras de iptables/ipvs:
Ele cria e mantém as regras de roteamento na máquina do nó (Node). Isso faz com que qualquer requisição enviada para o IP do Service seja redirecionada para um Pod ativo.
Lida com Load Balancing:
O kube-proxy balanceia o tráfego entre todos os Pods associados a um Service. Se um Pod morrer, ele ajusta as regras para ignorá-lo.
Como ele funciona?
O kube-proxy roda em cada nó do cluster e monitora o etcd para saber quais são os Services e os Pods relacionados. A partir disso, ele:
Configura regras no iptables ou usa o IPVS (mais eficiente para grandes clusters).
Encaminha o tráfego externo e interno para os Pods corretos.
Exemplo prático:
- Você tem um Service com dois Pods rodando (Pod-A e Pod-B).
- Quando um cliente faz uma requisição para o ClusterIP do Service (tipo 10.96.0.1), o kube-proxy redireciona o tráfego para um dos dois Pods.
- Se o Pod-A falhar, ele para de redirecionar para ele e só manda para o Pod-B.
Tipos de Services que o kube-proxy gerencia:
ClusterIP:
- Faz o serviço ficar acessível apenas dentro do cluster.
NodePort:
- Expõe o serviço externamente via uma porta fixa no Node.
LoadBalancer:
- Cria um Load Balancer externo (em nuvem) e distribui tráfego para os Nodes.
ExternalName:
- Resolve um DNS externo para o serviço.
Limitações:
- O kube-proxy só trabalha no nível de IP/porta. Ele não sabe nada sobre o conteúdo das requisições (tipo HTTP headers).
- Em clusters muito grandes, usar iptables pode ser menos eficiente. Nesse caso, o IPVS é uma opção melhor.
Resumo:
O kube-proxy é a cola que mantém a comunicação no cluster fluindo. Ele cuida das rotas e garante que os Services sempre conectem os usuários aos Pods certos, mesmo que haja mudanças ou falhas. Sem ele, os Pods seriam como ilhas isoladas sem comunicação entre si.
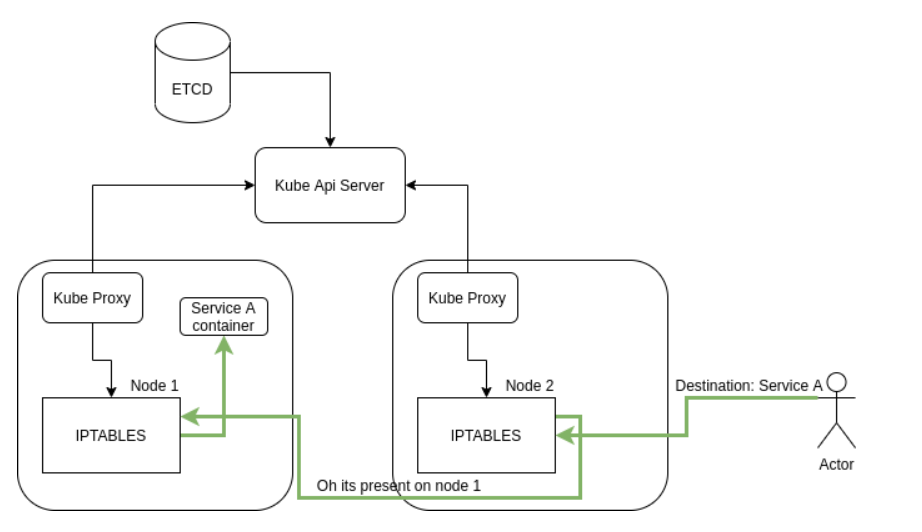
kube-scheduler:
O kube-scheduler é o “fazedor de escolhas” do Kubernetes. Ele é o cara que decide em qual Node do cluster cada Pod vai rodar. Quando você manda criar um Pod, o scheduler entra em ação para encontrar o lugar certo pra ele, levando em conta as condições do cluster e as configurações que você definiu.
Como o kube-scheduler funciona?
Escuta o API Server:
O kube-scheduler fica monitorando o etcd (via API Server) para encontrar Pods que ainda não têm um Node definido.
Analisa os Nodes disponíveis:
Ele avalia todos os Nodes no cluster pra ver quem está apto a receber o Pod. Isso inclui verificar:
- Recursos disponíveis: CPU, memória.
- Tolerâncias e afinidades: Se o Pod foi configurado para rodar em um Node específico ou evitar outro.
- Restrições: Labels, selectors, etc.
- Health do Node: O Node está funcionando? Ele pode aceitar novos Pods?
Decide onde colocar o Pod:
Depois de avaliar todas as opções, ele escolhe o Node mais apropriado e atualiza a configuração do Pod para apontar pra esse Node.
O que ele considera pra decidir?
- Requests e Limits:
Ele verifica os recursos mínimos (requests) que o Pod precisa e se encaixa no Node.
Node Affinity:
Você pode dizer que um Pod deve rodar em Nodes com uma label específica. Exemplo:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
– matchExpressions:
– key: disktype
operator: In
values:
– ssd
- Taints e Tolerations:
Nodes podem ser “marcados” pra rejeitar Pods, e só os Pods com tolerations vão ser aceitos. - Topology Spread Constraints:
Ele também tenta distribuir os Pods de forma equilibrada entre Nodes, zonas de disponibilidade, etc., dependendo da configuração.
Quando ele entra em ação?
Sempre que um Pod novo é criado ou um Node fica indisponível e o Pod precisa ser reposicionado. O kube-scheduler toma a decisão e o kubelet (no Node escolhido) assume a responsabilidade de rodar o Pod.
E se o kube-scheduler falhar?
Se o kube-scheduler estiver fora do ar, os Pods não vão ser agendados. Ou seja, eles ficam “presos” no estado Pending até que o scheduler volte e consiga designar um Node pra eles.
Resumo direto:
O kube-scheduler é o cérebro que faz os Pods encontrarem seu lugar no cluster. Ele analisa os Nodes, as regras que você configurou, e decide onde o Pod deve rodar, garantindo que os recursos sejam usados da melhor forma possível.
Kubelet:
O kubelet é o “executor de ordens” no Kubernetes. Ele roda em cada Node do cluster e é responsável por garantir que os containers do Pod realmente sejam executados. Em outras palavras, o kubelet é o cara que pega as instruções do Control Plane e as transforma em algo que roda de verdade no Node.
O que o kubelet faz?
Monitora o API Server:
Ele fica de olho no API Server pra saber quais Pods foram agendados pro Node onde ele está rodando.
Gerencia containers:
Quando o kube-scheduler escolhe um Node pra rodar um Pod, o kubelet pega as informações do Pod e pede pro container runtime (Docker, containerd, etc.) criar e executar os containers.
Mantém os Pods vivos:
O kubelet faz verificações constantes pra garantir que os Pods estão rodando como deveriam. Se algum container parar de funcionar, ele tenta recriar.
Relata o estado do Node:
Ele manda relatórios pro API Server sobre o status do Node: se está saudável, quais recursos estão disponíveis (CPU, memória, etc.), e se os Pods estão rodando sem problemas.
Gerencia volumes e configurações:
Ele também cuida de montar volumes (ex.: discos persistentes) e aplicar ConfigMaps ou Secrets nos Pods.
Como ele faz isso?
- O kubelet conversa com o container runtime instalado no Node (Docker, containerd, etc.) usando a CRI (Container Runtime Interface).
- Ele usa as definições de Pod (especificadas em YAML) pra saber:
- Qual imagem de container baixar.
- Quais volumes montar.
- Quais limites de recursos aplicar.
Exemplo prático:
O kube-scheduler manda um Pod pro Node.
O kubelet vê a configuração do Pod (via API Server).
Ele baixa a imagem do container (se não estiver localmente).
Pede pro container runtime iniciar o container.
Começa a monitorar o container:
- Se travar, ele reinicia.
- Se o Pod tiver uma liveness probe, ele usa pra verificar a saúde.
O que acontece se o kubelet falhar?
Se o kubelet parar, o Node “fica mudo”. Ele não consegue reportar seu status pro cluster, e o Kubernetes pode acabar tratando o Node como inativo. Consequência:
- Os Pods nesse Node podem ser realocados pra outros Nodes (dependendo da configuração).
Resumo direto:
O kubelet é o trabalhador no Node que faz o Kubernetes funcionar. Ele recebe ordens do Control Plane, gerencia os Pods e containers localmente, e garante que tudo esteja rodando do jeito que deveria. Sem ele, seu cluster não roda nada!
Container Runtime Interface (CRI):
A Container Runtime Interface (CRI) é tipo a ponte que conecta o Kubernetes ao software que realmente roda os containers, como o containerd ou o CRI-O. É o padrão que o kubelet usa pra se comunicar com qualquer “motor de containers”.
Antes do CRI, o Kubernetes era dependente do Docker, mas o CRI abriu o jogo: agora qualquer runtime que siga essa interface pode funcionar no Kubernetes.
Como o CRI funciona na prática?
O kubelet decide que precisa rodar um container em um Pod.
Ele usa o CRI pra mandar comandos pro runtime configurado no Node (tipo “inicia esse container”, “para esse outro”, etc.).
O runtime, seguindo as regras do CRI, executa o container e manda de volta informações como:
- ID do container.
- Logs.
- Status de execução (rodando, parado, crashou, etc.).
Principais componentes do CRI
Container Runtime:
O software que executa os containers no Node (ex.: containerd, CRI-O, ou outro que siga o CRI).
gRPC API:
O kubelet e o runtime conversam via uma API baseada em gRPC. Essa API define:
- Como criar e rodar containers.
- Como gerenciar imagens.
- Como lidar com logs e status.
Protocolos definidos:
O CRI padroniza funções essenciais, como:
- Gerenciar imagens (PullImage, RemoveImage).
- Criar, iniciar, ou deletar containers (RunPodSandbox, CreateContainer, etc.).
- Consultar status (ContainerStatus, ListContainers).
Por que isso é importante?
Com o CRI, o Kubernetes virou agnóstico de runtime, ou seja, não tá amarrado a nenhuma ferramenta específica. Isso trouxe várias vantagens:
- Mais flexibilidade: Pode usar o runtime que faz mais sentido pra sua infra (ex.: CRI-O pra clusters otimizados pro OpenShift ou containerd pra clusters vanilla).
- Independência do Docker: O Kubernetes não depende mais de um único runtime, como era antes.
Na prática: como escolher o runtime?
- containerd: É o runtime padrão e mais usado no Kubernetes. É leve, direto ao ponto, e mantido pela CNCF (mesma galera por trás do Kubernetes).
- CRI-O: É otimizado pro OpenShift e bem integrado ao ecossistema Red Hat.
- Docker + dockershim: Era o padrão antigamente, mas o suporte ao Docker foi descontinuado desde o Kubernetes 1.20.
Resumindo:
A CRI é o “tradutor universal” entre o Kubernetes e os runtimes de containers. Graças a ela, o kubelet pode usar qualquer runtime que siga o padrão, tornando o Kubernetes mais flexível e modular.
Bom, essa foi a parte 1 da série sobre Kubernetes. O Kubernetes pode parecer um pouco complexo à primeira vista, e é normal não entender tudo de imediato. Nesta parte, exploramos os componentes que formam o Kubernetes. Em breve, vamos colocar esse conhecimento em prática, manipulando e criando Pods.
Fique de olho para não perder a parte 2!