
🇬🇧 Kubernetes Part 1
🇧🇷 para ler este artigo em português clique aqui
In this series of articles, we will explore Kubernetes in 3 parts. Kubernetes is an incredibly powerful tool, but it can become complex if not explained in a clear way. To address the topic comprehensively and accessibly, I decided to create this series, with this being the first part. Here, I intend to explain what Kubernetes is, how to set up its initial configuration, its core concepts, and essential components. This is just the beginning of the journey. Let’s get started!
KUBERNETES PART 1
What is Kubernetes?
Kubernetes is like the conductor of a server orchestra. It is responsible for managing and orchestrating applications running in containers, like Docker. Imagine having multiple services and applications distributed across different machines, and wanting to ensure they are always running, new ones are added when needed, and outdated ones are updated or removed without disruption. Kubernetes handles this for you.
It automatically distributes tasks across servers, ensures everything runs smoothly, and even self-heals by restarting failing services. Additionally, it facilitates tasks like scaling applications (adding more “resources” where needed) and deploying new versions without taking everything down. It acts like a super assistant for managing infrastructure, allowing you to focus more on what truly matters.
Kubernetes Immutable Concept:
Immutable in Kubernetes is simple: instead of modifying something that already exists, it creates a new version. For example, if you want to update a container in a Deployment, Kubernetes doesn’t alter the running instance. It creates new Pods with the updated configuration, and once those new Pods are ready, it replaces the old ones.
This ensures you always have a “version history.” If something goes wrong, you can easily roll back. It’s like Kubernetes builds new versions of your applications without disrupting what is already running, keeping everything organized and predictable.
In practice, immutability in Kubernetes works like this:
Desired State Definition: You create or modify a YAML file (we’ll discuss this in Part 2) describing the resource you want to run (e.g., a Deployment). This file outlines everything: how many replicas you want, which image to use, etc.
Applying Configuration: When you submit this file to the cluster, Kubernetes compares what’s in the file with what’s already running on the cluster.
Immutable Update: If something changes in the file (e.g., a new version of the container image), Kubernetes starts creating new Pods with that updated configuration. The old Pods are not edited; they continue running until the new ones are ready.
Rolling Update: Once the new Pods are healthy and ready, Kubernetes starts shutting down the old Pods. This is called a rolling update and ensures nothing goes down at once.
Easy Rollback: If the new configuration fails, you can quickly revert to the previous version. Since each change creates something new, you always have a “backup” of the previous state.
The idea is that everything running in Kubernetes should be disposable and replaceable. Nothing is “adjusted” manually; everything is recreated based on what you described in the files. This ensures consistency and predictability in the environment.
A Bit of Fundamentals:
In Kubernetes, you have two ways to do things: imperative commands and declarative configurations. The difference is simple: one is more direct, like “do this now,” and the other is more planned, like “this is what I want, make it happen.”
Imperative Commands
These are commands you run directly in the terminal to do something instantly. It’s fast and to the point, but doesn’t leave a “trace” of what was done.
Example:kubectl create deployment my-app --image=nginx
Here, you are instructing Kubernetes to create the nginx Deployment. Easy and fast, but if you need to repeat this tomorrow, you’ll have to remember or document the command.
Advantages:
Great for quick tests.
No need for YAML files.
Disadvantages:
Hard to keep track of what was created.
Not reusable.
Declarative Configurations
Here, you write a YAML file that describes what you want in the cluster. Instead of saying “do this now,” you tell it “this is the state I want,” and Kubernetes handles everything to reach that state.
Example YAML:
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-app
spec:
replicas: 3
selector:
matchLabels:
app: my-app
template:
metadata:
labels:
app: my-app
spec:
containers:
- name: nginx
image: nginx
Then apply the file with:kubectl apply -f deployment.yaml
Advantages:
Easier to version in Git.
Reusable and more organized.
Disadvantages:
Requires more initial setup time.
Can seem more complex for beginners.
Summary
Imperative: “Do it now!” (quick but unorganized).
Declarative: “Here’s the plan, follow it!” (organized and ideal for production).
In daily use, imperative is good for quick tasks, but declarative is the way to go if you want scalability and control.
Kubectl:
Kubectl is your primary tool for everything in Kubernetes. From creating resources to troubleshooting, it has a command for everything. It’s like a Swiss Army knife: with it, you can do everything you need in the cluster.
It is the command-line tool you use to manage almost everything in the cluster. With kubectl, you can create, list, update, and delete Kubernetes resources, as well as monitor what is happening.
Basic Command Structure
The general syntax is:kubectl [command] [resource-type] [resource-name] [flags]
Examples:
Creating a Deployment:kubectl create deployment my-app --image=nginx
create→ Specifies that you want to create something.deployment→ The resource type you want to create.my-app→ The name you are giving to the resource.--image=nginx→ Specifies the container image to be used.
Listing Resources in the Cluster:kubectl get pods
get→ Requests to list resources.pods→ The resource type you want to view.
Details about a Specific Resource:kubectl describe pod my-pod
describe→ Displays detailed information about the resource.my-pod→ The name of the Pod you want to inspect.
Deleting a Resource:kubectl delete pod my-pod
delete→ Removes the specified resource.my-pod→ The name of the resource to be deleted.
Applying Configuration from a YAML File:kubectl apply -f deployment.yaml
apply→ Applies the declared configuration from the file.-f→ Specifies the path to the YAML file.
For more in-depth practice, Kubernetes has a comprehensive documentation about the command-line tool:
https://kubernetes.io/docs/reference/kubectl/
Kubernetes Components:
Control Plane:
The control plane is the brain of Kubernetes. It decides what happens in the cluster and ensures everything works as intended. Essentially, it manages the state of the cluster and the resources running within it.
How it works:
- Receives orders: When you apply a YAML (e.g.,
kubectl apply -f deploy.yaml), the control plane takes this request and registers it in the system as the desired state. - Thinks ahead: It compares what you requested (desired state) with what is currently running (current state). If they differ, it starts to correct.
- Makes things happen: It sends instructions to nodes (machines where Pods run) to create, delete, or adjust resources until everything is as you want.
Key Components:
- API Server: The component that listens to your commands (e.g.,
kubectl) and connects everything. - Scheduler: Determines which node each Pod should run on.
- Controller Manager: Manages automated processes, such as creating new Pods if one fails.
- etcd: The database that stores all cluster information (configurations, state, etc.).
In summary:
The control plane manages the cluster 24/7. It listens to what you want, checks what needs to be adjusted, and ensures everything functions properly. If something goes wrong, it tries to fix it by itself. It’s the ever-present leader that never sleeps.
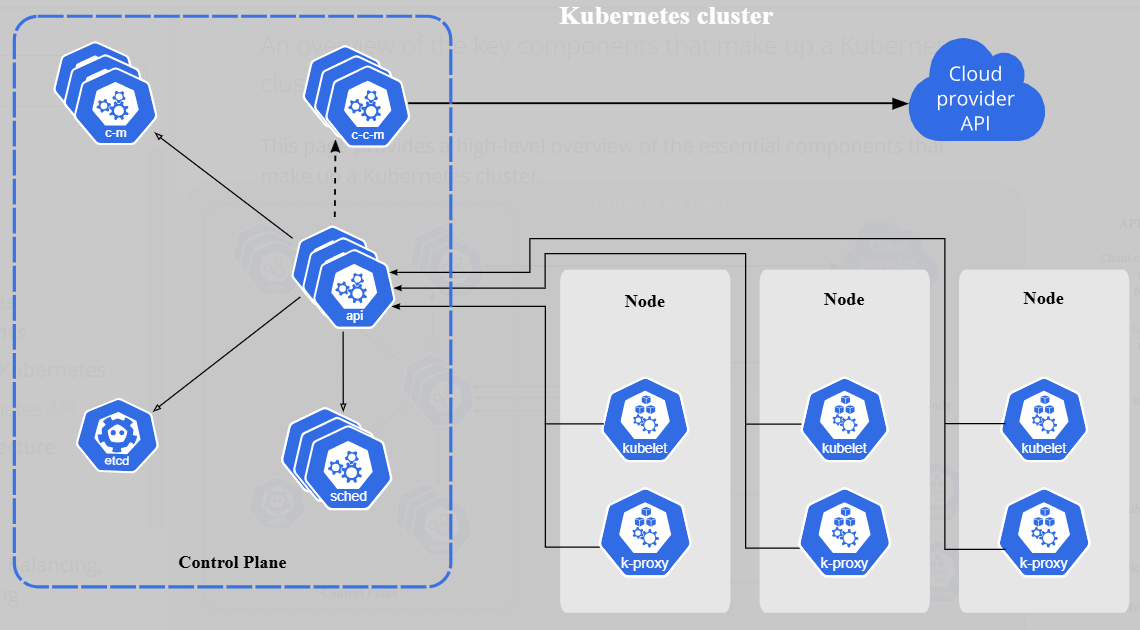
Don’t be afraid of this image, you’ll understand it soon.
Pod Concept
A Pod is the smallest unit in Kubernetes. It’s like the “box” where your applications live within the cluster. It’s not just a single container, but rather a layer that encapsulates one or more containers and ensures they work together as a unit.
How it works in practice?
1 Pod = 1 or more containers.
In most cases, you use only one container per Pod. However, if containers need to work together—for example, an app requiring a sidecar (e.g., a log collector)—you can place multiple containers within the same Pod.
Shared Communication and Resources:
- IP and Port Sharing:
All containers in a Pod share the same network, allowing them to communicate via localhost. For example, Container A can talk to Container B without exposing ports externally. - Shared Resources:
- Volumes: If you need to store data or share files between containers in a Pod, you use volumes.
- Configs: You can use ConfigMaps or Secrets to pass sensitive configurations.
Pod Resources:
Kubernetes provides tools to control resource usage (CPU, memory, etc.) within Pods.
- Requests: The minimum resources a Pod needs to run. When you define a request, Kubernetes ensures the Node has these resources available before allocating the Pod.
Example:resources: requests: memory: "256Mi" cpu: "500m" - Limits: The maximum resources a Pod can use. If a Pod tries to consume more than its limit, Kubernetes may throttle or terminate it (in case of memory overflow).
Example:resources: limits: memory: "512Mi" cpu: "1"
When is a Pod created?
Whenever you deploy something on Kubernetes, what really gets created in the cluster is a Pod. For example:
- A Deployment creates Pods for containers.
- A Job creates Pods to run a task.
What happens when a Pod dies?
If a Pod dies, goodbye! Kubernetes doesn’t revive Pods directly. It creates new ones if configured. For example:
- With a Deployment or ReplicaSet, new Pods are created automatically.
- A standalone Pod without a controller? It dies, and that’s it.
Kube-apiserver:
The kube-apiserver is like the entry point of Kubernetes. It receives all commands and requests, whether from kubectl, external applications, or other cluster components.
What does it do?
- Receives Commands: Whenever you perform an action in Kubernetes (e.g., creating a Pod or applying a Deployment), it is kube-apiserver that handles this request.
- Checks and Validates: It reviews what you’ve sent and ensures everything is correct. For example, if you try to create a Pod with incorrect settings, it will notify you.
- Writes to etcd: After validation, it saves the resource details in etcd (the cluster’s database). This is where Kubernetes stores all information.
- Communicates with other components: It informs other cluster components (like the scheduler and controllers) about changes to take the next actions.
Why is it important?
Without kube-apiserver, Kubernetes wouldn’t function. It acts as a bridge that translates your requests and ensures the entire cluster knows about them. Think of it like the central hub, ensuring all parts of Kubernetes operate smoothly.
Cloud Controller Manager:
The Cloud Controller Manager is one of the components of the Kubernetes Control Plane, connecting the cluster with cloud-specific services such as AWS, GCP, or Azure. It essentially bridges Kubernetes interactions with cloud infrastructure.
What does it do?
- Manages resources outside the cluster that are necessary for Kubernetes to function, like load balancers, storage volumes, and public IP addresses.
How it works:
The Cloud Controller Manager has several internal controllers handling different aspects:
- Node Controller: Ensures registered nodes (VMs) are active. If a VM is removed from the cloud, it cleans the reference in Kubernetes.
- Route Controller: Configures network routes between nodes so Pods can communicate.
- Service Controller: Manages cloud load balancers for services of type LoadBalancer.
- Volume Controller: Handles provisioning and connecting storage volumes (e.g., EBS on AWS, Persistent Disks on GCP) to Pods.
When does Cloud Controller Manager come into play?
Whenever you use Kubernetes resources relying on cloud infrastructure. Examples:
- Creating a Service with type: LoadBalancer → it configures the Load Balancer in the cloud.
- Adding a PVC → it provisions a disk automatically in the cloud backend.
- Deleting a node → it checks if the VM was removed and cleans it from the cluster.
Is it mandatory?
If running Kubernetes on bare-metal (no cloud), the Cloud Controller Manager doesn’t do anything since there’s no cloud integration. But for clusters in AWS, Azure, GCP, etc., it’s essential for automation.
Controller Manager:
The Controller Manager is the “multi-tasking manager” of Kubernetes. It is responsible for running controllers that handle various functions within the cluster. Each controller addresses a specific task, and the Controller Manager centrally manages them. It is a crucial component of the Control Plane for keeping the cluster running smoothly.
What is a controller?
A controller is essentially a loop that monitors the current state of a resource in the cluster and attempts to align it with the desired state. In Kubernetes, everything is based on the idea of desired state versus current state.
Example:
You want 3 replicas of a Pod running (desired state). If one of these Pods fails, the controller will detect that there are only 2 Pods running (current state) and will create another to balance the two states.
What does the Controller Manager do?
It’s like the “loop organizer,” running multiple controllers at once. Some of the main controllers it manages include:
- Replication Controller: Ensures the correct number of Pod replicas are running.
- Node Controller: Checks if cluster nodes (VMs) are active. If a node goes offline, it marks it as “NotReady.”
- Endpoints Controller: Updates Endpoint objects to connect services with the appropriate Pods.
- Service Account & Token Controllers: Manages service accounts and tokens necessary for authentication within the cluster.
- Job Controller: Ensures Jobs (one-time tasks) run until completion.
- Persistent Volume Controller: Manages the lifecycle of persistent volumes, connecting PVCs (Persistent Volume Claims) to PVs (Persistent Volumes).
How does it function?
It runs as a single process in the Control Plane.
All controllers are embedded within it.
It continuously monitors the current state of the cluster (via etcd) and ensures alignment with what you declare in YAML manifests.
When does the Controller Manager come into action?
Whenever something changes in the cluster. Examples:
- Deleting a Pod manually → The Replication Controller recreates it.
- A node fails → The Node Controller marks it as unavailable.
- Creating a PVC → The Persistent Volume Controller provisions a volume if possible.
etcd-cluster-persistence-storage:
etcd is the heart of Kubernetes. It is a fast, distributed key-value database storing the entire state of the cluster. Without it, Kubernetes would lose track of what is running, what resources exist, and how to align your desired state with the current state.
What is etcd in practice?
Think of it as a super-organized agenda: everything that happens or needs to happen in Kubernetes is recorded there. From which Pods should run to details like ConfigMaps, Secrets, and Node status.
Why is persistent storage important?
etcd requires persistence because:
- It holds the current state of the cluster. If etcd fails, Kubernetes forgets everything.
- It’s critical for disaster recovery. If the cluster breaks, the etcd backup restores everything.
Where and how to store etcd?
- Local: A fast disk on the server running etcd.
- Cloud: Persistent storage from the cloud, such as AWS EBS or GCP Persistent Disks.
- Etcd Clusters: For high availability, run an etcd cluster with 3 or 5 instances. This distributes data, prevents total loss in case of node failure, and keeps etcd functioning.
How does etcd work in Kubernetes?
The kube-apiserver is the only component that interacts directly with etcd.
It reads and writes to etcd to store and retrieve the state of the cluster.
Examples of data stored:
Deployment specifications, Pods, Services.
Secrets and configurations.
Status of each resource.
Golden Tip: Backups!
Since etcd is the “memory” of Kubernetes, regular backups are essential. Without them, you risk losing the entire state of the cluster. For large or production clusters, use automated tools like etcdctl snapshot.
kube-proxy
The kube-proxy is like the “router” of Kubernetes. It manages network rules within the cluster, ensuring that Services can distribute traffic to the correct Pods. Essentially, it handles the internal connection magic within the cluster, ensuring requests reach their intended destinations.
What does kube-proxy do?
- Traffic Distribution: When you create a Service, it ensures that traffic is routed to the associated Pods.
- Manages iptables/ipvs rules: It creates and maintains routing rules on the node machine. This ensures that any request sent to the Service’s IP is redirected to an active Pod.
- Handles Load Balancing: kube-proxy balances traffic among all Pods associated with a Service. If a Pod fails, it adjusts the rules to ignore it.
How does it work?
kube-proxy runs on each node in the cluster and monitors etcd to know which Services and Pods are related. From this, it:
- Configures rules in iptables or uses IPVS (more efficient for large clusters).
- Routes both external and internal traffic to the correct Pods.
Practical Example:
You have a Service with two Pods running (Pod-A and Pod-B).
When a client makes a request to the ClusterIP of the Service (e.g., 10.96.0.1), kube-proxy redirects the traffic to one of the two Pods.
If Pod-A fails, it stops redirecting traffic to it and only routes it to Pod-B.
Types of Services managed by kube-proxy:
- ClusterIP: Makes the service accessible only within the cluster.
- NodePort: Exposes the service externally via a fixed port on the Node.
- LoadBalancer: Creates an external Load Balancer (in the cloud) and distributes traffic to the Nodes.
- ExternalName: Resolves an external DNS to the service.
Limitations:
kube-proxy works solely at the IP/port level. It doesn’t understand the contents of requests (such as HTTP headers).
In very large clusters, using iptables can be less efficient. In this case, IPVS is a better option.
Summary:
kube-proxy is the glue that keeps communication flowing within the cluster. It handles routes and ensures that Services always connect users to the correct Pods, even in the event of changes or failures. Without it, Pods would be isolated islands with no communication between them.
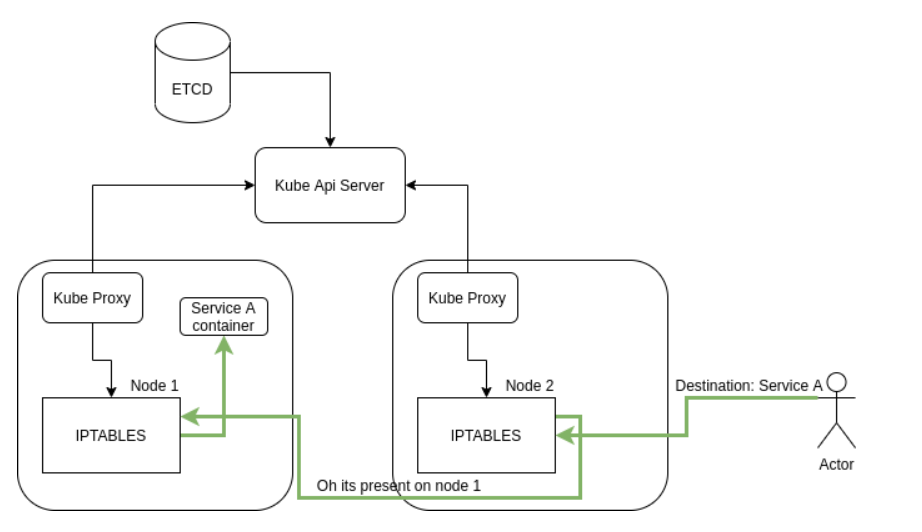
Sure! Here’s the continuation in English:
kube-scheduler:
The kube-scheduler is the “decision maker” of Kubernetes. It is responsible for deciding on which Node in the cluster each Pod will run. When you create a Pod, the kube-scheduler takes action to find the right place for it, considering the cluster conditions and the configurations you have defined.
How does the kube-scheduler work?
- Listens to the API Server: The kube-scheduler monitors etcd (via the API Server) to find Pods that do not yet have a Node assigned.
- Analyzes available Nodes: It evaluates all Nodes in the cluster to determine which is capable of running the Pod. This includes checking:
- Available resources: CPU, memory.
- Tolerances and affinities: Whether the Pod was configured to run on a specific Node or avoid another.
- Constraints: Labels, selectors, etc.
- Node health: Is the Node functioning properly? Can it accept new Pods?
- Decides where to place the Pod: After evaluating all options, the kube-scheduler selects the most appropriate Node and updates the Pod configuration to point to that Node.
What does it consider when making decisions?
- Requests and Limits: The kube-scheduler checks the minimum (requests) resources needed by the Pod and whether it fits into the Node.
- Node Affinity: You can specify that a Pod should run on Nodes with a specific label. Example:
affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: disktype operator: In values: - ssd - Taints and Tolerations: Nodes can be “tainted” to reject Pods, and only Pods with tolerations will be accepted.
- Topology Spread Constraints: It also seeks to distribute Pods evenly across Nodes, availability zones, etc., depending on the configuration.
kubelet:
The kubelet is the “executor” in Kubernetes. It runs on each Node in the cluster and is responsible for ensuring that the containers of the Pods are actually executed. In other words, the kubelet takes instructions from the Control Plane and turns them into actions that run on the Node.
What does the kubelet do?
- Monitors the API Server: It watches the API Server to know which Pods have been scheduled to the Node it is running on.
- Manages containers: When the kube-scheduler selects a Node to run a Pod, the kubelet retrieves Pod information and requests the container runtime (Docker, containerd, etc.) to create and run containers.
- Keeps Pods alive: The kubelet performs constant checks to ensure that Pods are running as expected. If any container stops working, it attempts to recreate it.
- Reports Node status: It sends reports to the API Server about the status of the Node: whether it’s healthy, what resources are available (CPU, memory, etc.), and if Pods are running smoothly.
- Manages volumes and configurations: It also handles mounting volumes (e.g., persistent disks) and applying ConfigMaps or Secrets to Pods.
How does it work?
The kubelet communicates with the container runtime installed on the Node (Docker, containerd, etc.) using the CRI (Container Runtime Interface). It uses Pod definitions (specified in YAML) to know:
- Which container image to download.
- Which volumes to mount.
- Which resource limits to apply.
Practical example:
The kube-scheduler sends a Pod to a Node.
The kubelet reads the Pod configuration (via API Server).
It downloads the container image (if not already local).
It requests the container runtime to start the container.
It begins monitoring the container:
If it freezes, it restarts it.
If the Pod has a liveness probe, it uses that to check health.
What happens if the kubelet fails?
If the kubelet stops working, the Node becomes “unreachable.” It can no longer report its status to the cluster, and Kubernetes may treat the Node as inactive. As a result, Pods on that Node may be relocated to other Nodes (depending on configuration).
Summary:
The kubelet is the worker on the Node that makes Kubernetes function. It receives instructions from the Control Plane, manages Pods and containers locally, and ensures everything runs smoothly. Without it, your cluster cannot run anything!
Well, this was part 1 of the series on Kubernetes. Kubernetes might seem a bit complex at first glance, and it’s normal not to understand everything right away. In this part, we explored the components that make up Kubernetes. Stay tuned for part 2, where we will put this knowledge into practice by managing and creating Pods.
Stay tuned so you don’t miss part 2!